
Structured Data is a way of adding context to files served on the web so that computers (primarily but not only search engines) can respond to what your content means.
Google, for example, will alter and improve how your site appears in search results based on the context you give your data. And if your site is considered authoritative can use the data to build the knowledge cards it sits alongside other search results.
This blog is only authoritative for being unread but I've not worked with structured data and thought I'd investigate.
There are several formats with which you can add structured data which typically use the schema.org vocabulary. Google prefers JSON-LD which is added to the page in a script tag as opposed to, for example, Microdata which decorates the HTML.
Here is an (example taken from schema.org):
<div itemscope itemtype="http://schema.org/ScreeningEvent">
<h1 itemprop="name">Jaws 3-D"</h1>
<div itemprop="description">Jaws 3-D shown in 3D.</div>
<p>Location: <div itemprop="location" itemscope itemtype="http://schema.org/MovieTheater">
<span itemprop="name">ACME Cinemas 10</span>
<span itemprop="screenCount">10</span>
</div>
</p>
<div itemprop="workPresented" itemscope itemtype="http://schema.org/Movie">
<span itemprop="name">Jaws 3-D</span>
<link itemprop="sameAs" href="www.imdb.com/title/tt0085750/"/>
</div>
<p>Language: <span itemprop="inLanguage" content="en">English</span></p>
<p>Film format: <span itemprop="videoFormat">3D</span></p>
</div>
The same markup in JSON-LD:
<script type="application/ld+json">
{
"@context:": "http://schema.org",
"@type": "ScreeningEvent",
"name": "Jaws 3-D",
"description": "Jaws 3-D shown in 3D."
"location": {
"@type": "MovieTheater",
"name": "ACME Cinemas 10",
"screenCount": 10
},
"workPresented": {
"@type": "Movie",
"name": "Jaws 3-D",
"sameAs": "www.imdb.com/title/tt0085750/"
},
"inLanguage": "en",
"videoFormat": "3D"
}
</script>
Since the aim is to add this data to a Jekyll site where the HTML is generated from markdown adding Microdata would most likely be a massive faff. But adding a script tag should be trivial.
First, the home page.
<script type="application/ld+json">
{ "@context": "http://schema.org",
"@type": "Blog",
"keywords": "software engineering agile refactoring c# ruby javascript",
"url": "https://pauldambra.github.io",
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://pauldambra.github.io"
},
"author": {
"@type": "Person",
"name": "Paul D'Ambra",
"sameAs": [
"https://twitter.com/pauldambra",
"https://github.com/pauldambra",
"https://plus.google.com/u/0/+PaulDAmbraPlus"
]
}
}
</script>
The above can be dropped straight into the index.html that the home page is generated from.
It says that it use schema.org, is describing a blog, which has a bunch of keywords and is at a particular URL. It advertises that the main thing about this webpage is the page itself. And lists that I'm the author and that I can be identified at a set of other locations (twitter, github, and google+)
Pretty straightforward since it is totally static information.
Next, each blog post
There's more to grok here…
{% assign wordcount = include.content | number_of_words %}
<script type="application/ld+json">
{
"@context":"http://schema.org",
"@type":"BlogPosting",
"headline":"{{ include.headline }}",
"genre":"{{ include.category }}",
"keywords":"{{ include.keywords }}",
"wordCount":"{{ wordcount }}",
"url":"https://pauldambra.github.io{{ include.link }}",
"datePublished":"{{ include.date | | date: '%Y-%m-%d' }}",
"author":{
"@type":"Person",
"name":"Paul D'Ambra",
"sameAs":[
"https://twitter.com/pauldambra",
"https://github.com/pauldambra",
"https://plus.google.com/u/0/+PaulDAmbraPlus"
]
},
"publisher":{
"@type":"Person",
"name":"Paul D'Ambra",
"sameAs":[
"https://twitter.com/pauldambra",
"https://github.com/pauldambra",
"https://plus.google.com/u/0/+PaulDAmbraPlus"
],
"logo": {
"@type": "ImageObject",
"contentUrl": "https://pauldambra.github.io/images/logo.png",
"url": "https://pauldambra.github.io"
}
},
"image":{
"@type":"ImageObject",
"contentUrl":"https://pauldambra.github.io/images/cardboard.jpg",
"url":"https://pauldambra.github.io",
"height":"450",
"width":"1000"
},
"mainEntityOfPage":{
"@type":"WebPage",
"@id":"https://pauldambra.github.io{{ include.link }}"
},
"articleBody":"{{ include.content | strip_html | xml_escape | normalize_whitepace | strip_newlines | strip }}"
}
</script>
As with the index page the context and type is set. That determines which properties are relevant. Also best to run the markup through the Google testing tool to make sure that you have included the properties Google requires.
The above is pasted into an html file in the _includes folder. And added to the layout used to render BlogPosts
{%
include structuredData.html
headline=page.title
genre=page.category
keywords=page.keywords
content=page.content
link=page.permalink
date=page.date
%}
BlogPosts (i.e. those items in the _posts folder) have a bunch of variables either automatically available or added in the post's YAML frontmatter. These are passed on into the structuredData include and referenced inside it as include.provided_name
That's not quite everything
The home page now has some data about the site itself but there's nothing in the markup to indicate that it is made up of a list of the site's published blog posts.
My solution to this highlights nicely how powerful the liquid templating language can be with a very limited set of operators and filters.
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "ItemList",
"itemListElement": [
{{ items }} <!-- see below -->
]
}
</script>
This adds a second script tag to hold the item list of blog postings. It is then necessary to loop over each post in site.posts and add an entry for that item.
But an array with a trailing comma is not valid JSON+LD and including a template here ends up with a trailing comma.
The solution is led by two things:
- Liquid provides the join filter which correctly joins an array without adding a trailing separator
- You can only initialise an array by splitting a string
so…
{% assign items = "" %}
{% for post in site.posts %}
{% capture list_item %}
{%
include blogListItem.html
index=forloop.index
url=post.url
title=post.title
date=post.date
%}
{% endcapture %}
{% assign items = items | append: list_item | append: "|||" %}
{% endfor %}
{% assign items = items | split: "|||" | join: ',' %}
- create an empty string
- loop over
site.posts - for each post capture the result of populating a
blogListIteminclude into a string - append that to the original string with a known separator
- then split that string
- then join that array with commas
- that can then be output into the script tag above
There may well be a different way of doing that. It seems a bit bonkers but it works…
Do the search engines use it?
I've submitted the site for crawling since adding structured data and Google has so far picked up the home page and four of the articles.
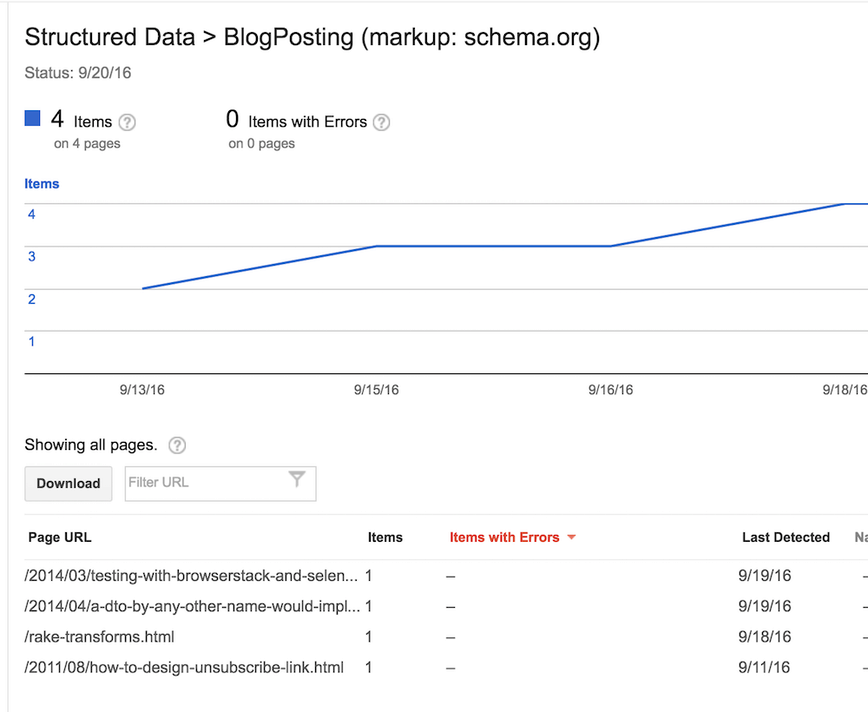
Several days on and there's no obvious change in how my site places in search rankings or how Google displays it but…
- their documentation says it can take some time and I've seen other people talking about it taking more than 10 days
- as above this site isn't authoritative for anything so I may not be crossing a threshold of importance for processing or be at the back of a very long queue.
Anyway, I think Structured Data, as well as being interesting, is a prerequisite for getting AMP set up and that's next up…