
TokuMX is an
"open source, high-performance distribution of MongoDB".
On a current project we're using MongoDB and, as the system is likely to scale fairly heavily, worrying (primarily) about storage. So, I picked up a task to compare MongoDB and TokuMX.
My test machine was a MBP with an SSD and 16GB RAM (Hear me roar!). I created a Debian 7 VM using VMware Fusion with 2GB RAM and then cloned it so that I had two identical linux servers.
I installed MongoDB on one and TokuMX on the other.
A NodeJS script was used to repetitively insert 6000 records and then query over the data in a single collection while only one of the two servers was powered on. I didn't clear out the databases between runs although this didn't appear to impact on the results. The script used is available on GitHuband feedback on better tests or mechanism for performing them is welcome!
The tests were run using asynchronous queues with varying levels of concurrency in order to try and simulate a relatively realistic load.
Update 2021: The data gathered used to be found on Google Docs but the link is dead now. It must have been in my FootClicks google account :'( Sorry posterity
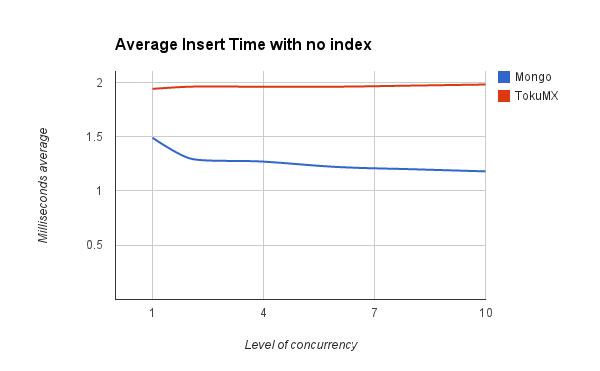
The first set of tests were run against a collection with no indexes set.
This first test showed that TokuMX query time was much better when searching on a non-indexed field.
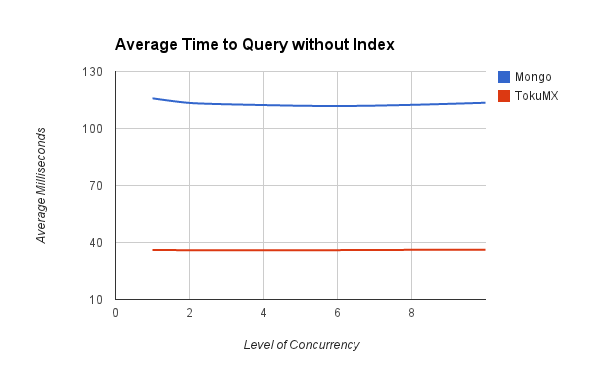
This performance difference larger disappeared when querying an indexed property.
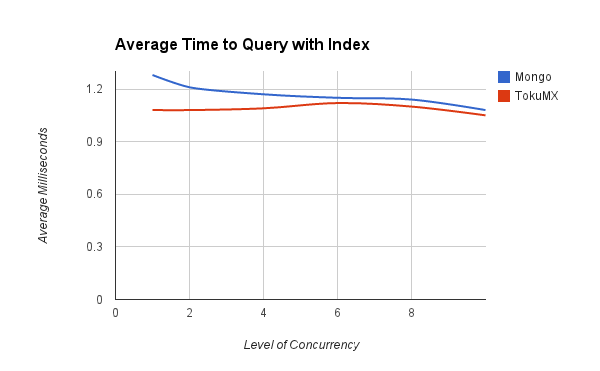
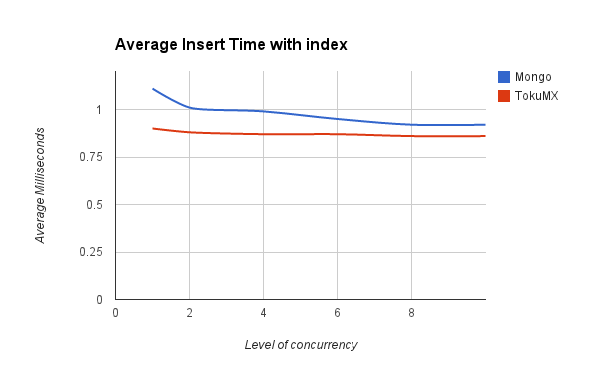
TokuMX was still slightly ahead and across all of these datasets was much less affected by the level of concurrency in use.
The real stand out difference here was looking at the amount of storage being used.
After the sets of tests against each server I ran du -shb /data/db to get the size of the entire database in bytes.
MongoDB was using 10303 bytes per record stored and TokuMX only 104 bytes per record stored.
These might not be the best measures to use or the best way to gather the data (and I'll gladly try other mechanisms) but on a first glance it appears there is a compelling case to consider using TokuMX over MongoDB